
Dealing with I/O when writing Nuclei 'network' templates
How to properly deal with inputs and outputs when writing Nuclei 'network' templates (and a fix for Nuclei's core!)

During my research on honeypots detection, I had to create several Nuclei templates for a variety of network protocols. I discovered that properly writing inputs and reading outputs might be slightly more complex than it seems. There are a few things to bear in mind, which I would like to share in this post.
Yet, why is this useful? Nuclei is extremely practical for quickly verifying vulnerabilities, misconfigurations, or whether an application responds as expected to certain HTTP or TCP packets. There are thousands of templates for HTTP requests, which are well-documented with plenty of examples. However, this is not the case for 'network' templates, we'll be delving into these today.
INPUTS
The input is the chunk of bytes we will send to the target application. This can be provided as an ASCII string of characters ('text') or as a hexadecimal string ('hex').


Inputs are a YAML array, and it is possible to specify several.
For example:

Each string will be sent one after the other to the target. You might expect the target to respond to each of these packets individually; we will delve into this shortly.
Now, you might be wondering, where do those strings I use for the input come from? It depends on what you’re testing. When using TCP packets, you will have to speak the ‘language’ of the targeted protocol. To obtain these packets for use in your Nuclei template, you’ll likely first analyze the network traffic during your test to extract the right packets. For this, the most common tool is the popular traffic analyzer, Wireshark. For less complex protocols or simpler cases, you might want to give network-fingerprint a try.
Generally, creating the input part of the template is quite straightforward. However, reading the output and properly matching it with your expected response can sometimes bring issues. Let's jump into it.
OUTPUTS
According to Nuclei’s syntax reference, there are three properties to read the output: read, read-size, and read-all. The most commonly implemented are read and read-size. However, people often tend to confuse these two (well, the difference is not immediately apparent at first sight!), and incorrect usage may compromise the template's effectiveness.
In the simplest case, you might not need to specify any of those, and ‘read-size:1024’ will implicitly be used (which works for most cases). Yet, what’s the actual difference between the three options?
To start with, read is a property of network.Input() and, in case it is used, should be placed within each input statement. On the other hand, read-size and read-all are properties of network.Request(), therefore, they are placed outside the list of inputs.

As mentioned, read-size:1024 will be the default. In case you need to read more bytes (because what you are looking for in the output is not within the first 1024 bytes), you can provide a different size (for example, read-size:2048) or simply use read-all:true, which will read the entire output regardless of its size. Most cases are actually resolved using the read-size property, so what is read used for? Furthermore, the template above - while still working fine in this case - is not properly structured, as using read-size and read together in this way doesn’t really make sense.
It seems there are a few cases where it could make sense to use the read property instead. Let’s see two examples: 1) Matching strings in the response to specific inputs; 2) Using the response from an input to create the next request.
USING THE READ PROPERTY: CASE 1
At the beginning of this post, I shared an image with an example of multiple input requests; this belongs to the ADBHoney-shell detector I developed weeks ago. It sends multiple requests to the target and then matches a chunk of bytes that comes in the response to the last request.

As we can see, there is a read-size:1024 statement in the template. It will read, as seen below, the response to all the requests up to 1024 bytes in total, and then match the expected bytes in the response.

What if we would like to also match the string '=starltexx;ro.product.model=SM-G960F' that comes in the response to the second request? We could simply add one more matcher with this string, and it might work, as long as the response does not surpass 1024 bytes. However, this is where read plays a role! It would be best to use the read attribute, assign a name to the responses, and indicate to the matcher where to find each string. The code would look as follows:

The first modification, outlined in red, involves reading 512 bytes from the response of the second request and naming this "info". Then, in the matchers section, we indicate to look into the part labeled 'info' for the desired string.
That was easy. However, identifying the last chunk of bytes has now become slightly more complicated in this way. This is because ADB responds with two packets (OKAY and WRTE statements) to our last request. Therefore, if we want to match bytes in the last packet (WRTE), we first need to read and ‘skip' the OKAY response.

That’s the reason behind writing two read statements in the template after sending the last packet to the target. The last response is named 'shell-response'. In the matchers section, we specify such a name to match the expected chunk of bytes in this part.
As we can see, it is possible to use the structure of inputs to read from the socket without actually sending data. This approach was particularly useful in this scenario, where the target replies with more than one packet, and we need to match bytes in the last response.

In conclusion, for this case, I believe the read property can be quite useful in complex situations where it's necessary to read specific bytes from certain responses in a series of network packets. If such complexity isn't required, I highly recommend using read-size instead, as it tends to be less prone to failure. Sometimes, the read property can lead to timeouts, especially if you're not reading the exact amount of bytes (since Nuclei keeps waiting for more bytes, resulting in a timeout eventually).
A few weeks ago, I raised an issue related to this in the official Nuclei repository, which was addressed in the release 3.1.2. However, in certain cases, depending on the network protocol you're working with, this issue might still occur.
USING THE READ PROPERTY: CASE 2
Let’s jump into the second use case for the read property: Using the response from one input to create the subsequent request.
This is another complex scenario where - for example - you might be dealing with a network protocol that requires exchanging a few packets, including a challenge, to establish a connection. In such cases, it’s often necessary to take a portion of the target's response, which contains the challenge, and send it back in your subsequent request.
I've crafted a simple example to demonstrate this particular case:
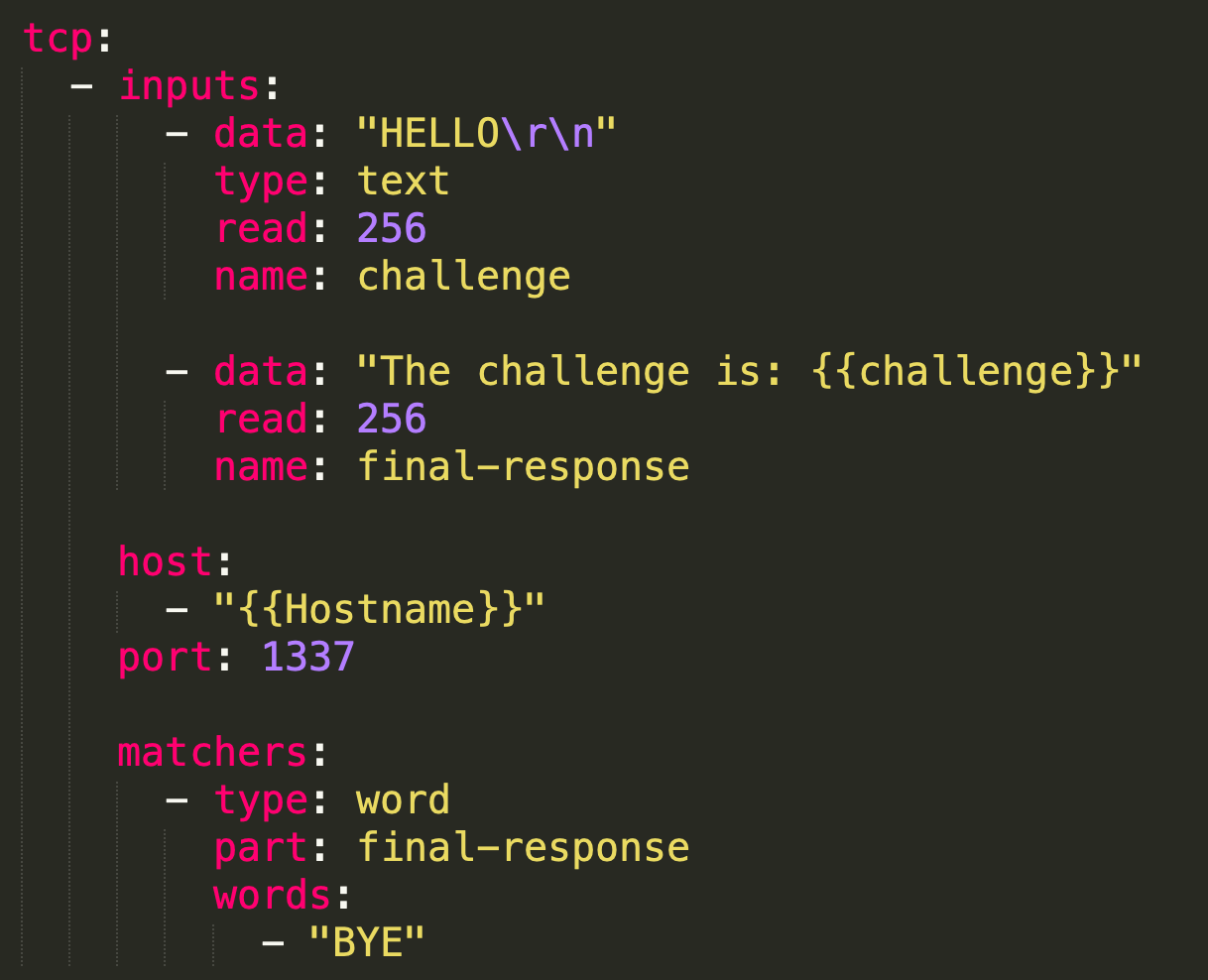
As observed, we read 256 bytes from the response of the first packet and name it “challenge”. Then, we use these received bytes into our second request. The matchers section isn’t of much importance in this example; the key aspect is how we can utilize the response from one packet for a subsequent request. Here's how it looks like when we use netcat for testing:

We successfully receive back the challenge part.
That’s all. I don’t want to extend this post any further. I hope you find these 'advanced' tips for developing Nuclei network templates useful :)